Training Go2-W: Hybrid Wheel-Leg Locomotion Policy
ROSCon India 2025 Workshop Prep - Part 3 of 4
The Challenge: Hybrid Locomotion
Training the Go2-W is fundamentally different from training standard quadrupeds. The policy must learn to:
- Roll on wheels when efficient (flat terrain, high speed)
- Walk on legs when necessary (obstacles, rough terrain)
- Coordinate both seamlessly during transitions
┌─────────────────────────────────────────────────────────────┐
│ GO2-W HYBRID LOCOMOTION MODES │
│ │
│ MODE 1: WHEEL ONLY MODE 2: LEG ONLY │
│ ──────────────────── ─────────────── │
│ ○═══○ ○═══○ /\ /\ │
│ ↓ ↓ / \ / \ │
│ Fast, efficient Obstacles, stairs │
│ Flat terrain Rough terrain │
│ │
│ MODE 3: HYBRID (The Goal!) │
│ ────────────────────────── │
│ Wheels roll + legs stabilize │
│ Automatic mode selection based on terrain │
│ │
└─────────────────────────────────────────────────────────────┘- Part 1: Isaac Sim vs Isaac Lab
- Part 2: Go2-W ROS 2 Interface
- Part 3: Training Go2-W Locomotion ← You are here
- Part 4: Go2-W Sim-to-Real
robot_lab: The Key to Go2-W Training
Standard Isaac Lab does not include Go2-W environments. You must use the robot_lab extension.
During workshop prep, we hit several issues you should know about:
Container is Ephemeral - Isaac Lab containers are removed when stopped. Only bind-mounted folders survive.
robot_lab Must Be on Host - Cloning inside the container = lost on restart. We add a bind mount to make it persistent.
Use robot_lab’s Scripts - Isaac Lab’s default
train.pydoesn’t import robot_lab environments. You must userobot_lab/scripts/.../train.py.Terminal Fix - We added
TERM=xterm-256colortodocker-compose.yamlto fix “xterm-kitty unknown terminal” errors.
Installation with Persistent Storage
The Isaac Lab container is ephemeral - files are lost when it stops. To make robot_lab persist, we use a bind mount.
Step 1: Clone on HOST (not inside container)
# On your HOST machine (not in container!)
cd ~/docker/isaac-lab/IsaacLab
git clone https://github.com/fan-ziqi/robot_lab.gitStep 2: Add Bind Mount to docker-compose.yaml
Edit ~/docker/isaac-lab/IsaacLab/docker/docker-compose.yaml and add this bind mount in the x-default-isaac-lab-volumes section:
- type: bind
source: ../robot_lab
target: ${DOCKER_ISAACLAB_PATH}/robot_labStep 3: Restart Container
cd ~/docker/isaac-lab/IsaacLab
python3 docker/container.py stop
python3 docker/container.py start
python3 docker/container.py enterStep 4: Install robot_lab (inside container)
# Inside container
cd /workspace/isaaclab
/workspace/isaaclab/_isaac_sim/python.sh -m pip install -e robot_lab/source/robot_labThe robot_lab folder persists (it’s on your host), but you may need to re-run the pip install:
/workspace/isaaclab/_isaac_sim/python.sh -m pip install -e robot_lab/source/robot_labAvailable Go2-W Environments
| Environment | Terrain | Use Case |
|---|---|---|
RobotLab-Isaac-Velocity-Flat-Unitree-Go2W-v0 |
Flat | Initial training |
RobotLab-Isaac-Velocity-Rough-Unitree-Go2W-v0 |
Rough | Advanced training |
Understanding the 16-DoF Action Space
Unlike standard quadrupeds (12 actions), Go2-W requires 16 actions:
┌─────────────────────────────────────────────────────────────┐
│ GO2-W ACTION SPACE (16D) │
├─────────────────────────────────────────────────────────────┤
│ │
│ LEG ACTIONS (12D) - Position Control │
│ ───────────────────────────────────── │
│ FL: [hip, thigh, calf] → 3 actions │
│ FR: [hip, thigh, calf] → 3 actions │
│ RL: [hip, thigh, calf] → 3 actions │
│ RR: [hip, thigh, calf] → 3 actions │
│ ───────────── │
│ 12 total │
│ │
│ WHEEL ACTIONS (4D) - Velocity Control │
│ ────────────────────────────────────── │
│ FL_wheel_velocity → 1 action │
│ FR_wheel_velocity → 1 action │
│ RL_wheel_velocity → 1 action │
│ RR_wheel_velocity → 1 action │
│ ───────────── │
│ 4 total │
│ │
│ TOTAL: 16 ACTIONS │
└─────────────────────────────────────────────────────────────┘Key Difference: Control Modes
| Component | Control Mode | Output Range | Notes |
|---|---|---|---|
| Legs (12) | Position | ±0.25 rad from nominal | PD control to target |
| Wheels (4) | Velocity | ±2.5 m/s | Continuous rotation |
Observation Space (~53D)
The Go2-W requires additional observations beyond standard quadrupeds:
┌─────────────────────────────────────────────────────────────┐
│ GO2-W OBSERVATION SPACE (~53D) │
├─────────────────────────────────────────────────────────────┤
│ │
│ STANDARD QUADRUPED OBSERVATIONS │
│ ─────────────────────────────── │
│ Base linear velocity (3D) → [vx, vy, vz] │
│ Base angular velocity (3D) → [wx, wy, wz] │
│ Gravity projection (3D) → Body frame gravity │
│ Velocity command (3D) → [cmd_vx, cmd_vy, cmd_wz]│
│ Leg joint positions (12D) → All leg joints │
│ Leg joint velocities (12D) → All leg joints │
│ ───── │
│ 36D (standard) │
│ │
│ GO2-W SPECIFIC OBSERVATIONS (NEW) │
│ ───────────────────────────────── │
│ Wheel velocities (4D) → Actual wheel speeds │
│ Wheel torques (4D) → Effort feedback │
│ Slip detection (4D) → Per-wheel slip signal │
│ Previous leg actions (12D) → Last leg commands │
│ Previous wheel actions (4D) → Last wheel commands │
│ ───── │
│ ~17D (Go2-W specific) │
│ │
│ TOTAL: ~53D │
└─────────────────────────────────────────────────────────────┘Why Wheel Observations Matter
| Observation | Purpose |
|---|---|
| Wheel velocities | Detect if wheels are spinning freely (slip) |
| Wheel torques | Infer terrain resistance (mud vs concrete) |
| Slip detection | Trigger transition to legged locomotion |
Reward Function Design
The reward function is critical for hybrid locomotion. It must encourage:
- ✅ Rolling when efficient
- ✅ Walking when necessary
- ✅ Smooth transitions between modes
Reward Components
┌─────────────────────────────────────────────────────────────┐
│ GO2-W REWARD FUNCTION │
├─────────────────────────────────────────────────────────────┤
│ │
│ POSITIVE REWARDS (Encourage) │
│ ────────────────────────────── │
│ Velocity tracking +1.0 r = exp(-||v_cmd - v||²) │
│ Angular tracking +0.5 r = exp(-||ω_cmd - ω||²) │
│ Smooth motion +0.1 Penalize action jerk │
│ │
│ NEGATIVE REWARDS (Discourage) │
│ ────────────────────────────── │
│ Energy penalty -0.01 r = -Σ(τ²) ← KEY FOR HYBRID │
│ Vertical velocity -2.0 Don't bounce │
│ Roll/pitch -0.05 Stay level │
│ Slip penalty -0.5 Punish wheel slip ← NEW │
│ Mode switching -0.1 Discourage thrashing ← NEW │
│ │
└─────────────────────────────────────────────────────────────┘The Energy Penalty: Key to Hybrid Behavior
A properly tuned energy penalty naturally teaches the robot: - Roll on flat ground → Wheels are more energy-efficient - Walk over obstacles → Legs engage when wheels slip
This emerges from optimization, not explicit mode switching!
# Energy penalty encourages efficient locomotion
def energy_reward(torques):
# Wheels use less energy for same speed on flat ground
# Legs use less energy climbing obstacles
return -0.01 * torch.sum(torques ** 2, dim=1)Slip Penalty: Preventing Wheel Spin
def slip_reward(wheel_cmd_vel, wheel_actual_vel):
# If commanded velocity >> actual velocity, wheels are slipping
slip = torch.abs(wheel_cmd_vel - wheel_actual_vel)
return -0.5 * torch.sum(slip, dim=1)Training Commands
You must use robot_lab’s train.py, not Isaac Lab’s default one. The robot_lab scripts properly import the Go2-W environments.
Quick Test (Development)
# Inside container
cd /workspace/isaaclab
# Use robot_lab's train script (NOT the isaaclab one!)
./isaaclab.sh -p robot_lab/scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Flat-Unitree-Go2W-v0 \
--num_envs=16 \
--max_iterations=100This launches Isaac Sim with 16 Go2-W robots training in parallel:
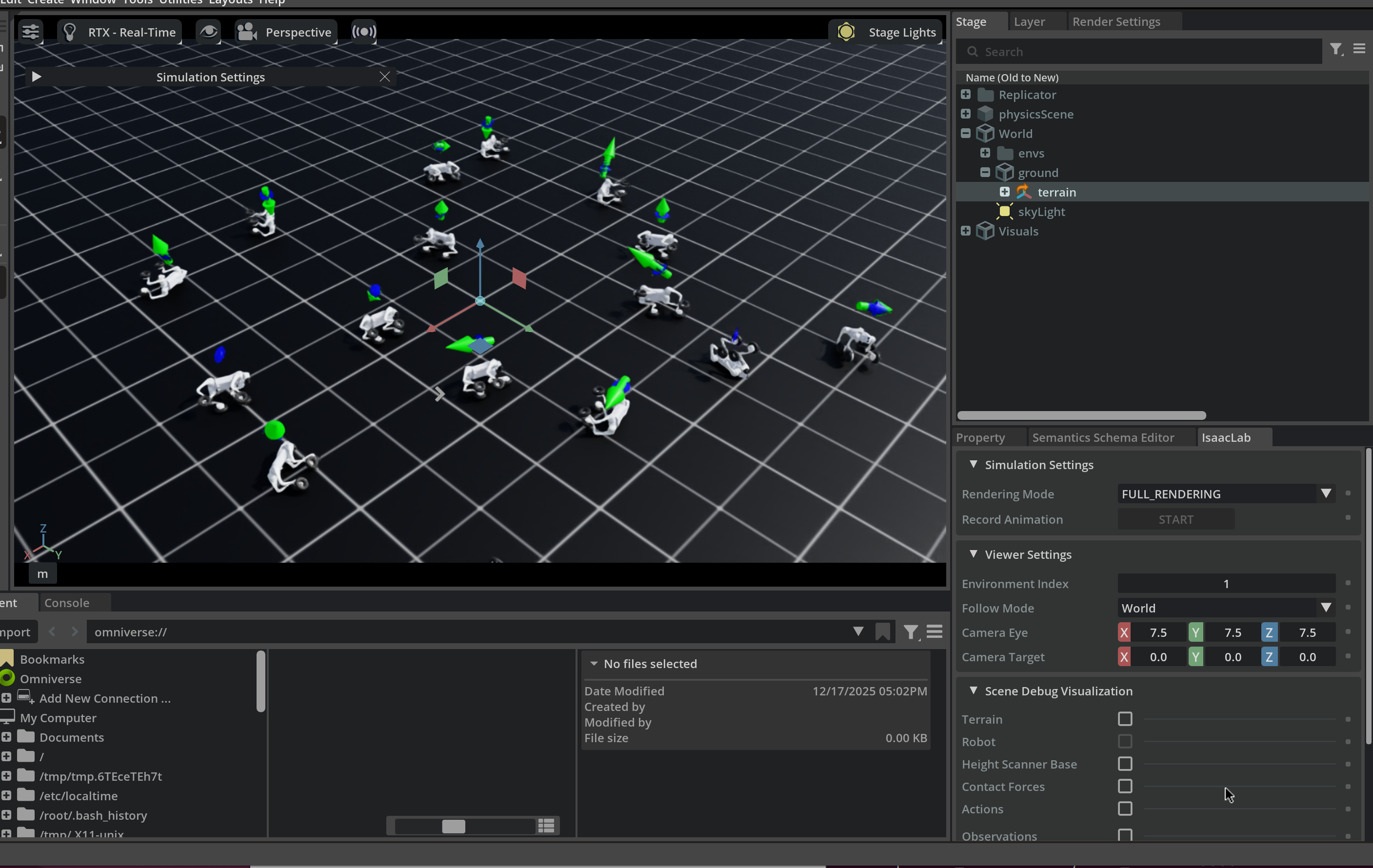
Full Training (Flat Terrain First)
./isaaclab.sh -p robot_lab/scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Flat-Unitree-Go2W-v0 \
--num_envs=4096 \
--headlessAdvanced Training (Rough Terrain)
./isaaclab.sh -p robot_lab/scripts/reinforcement_learning/rsl_rl/train.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2W-v0 \
--num_envs=4096 \
--headlessTraining Metrics
After ~100 iterations, you should see metrics like this:
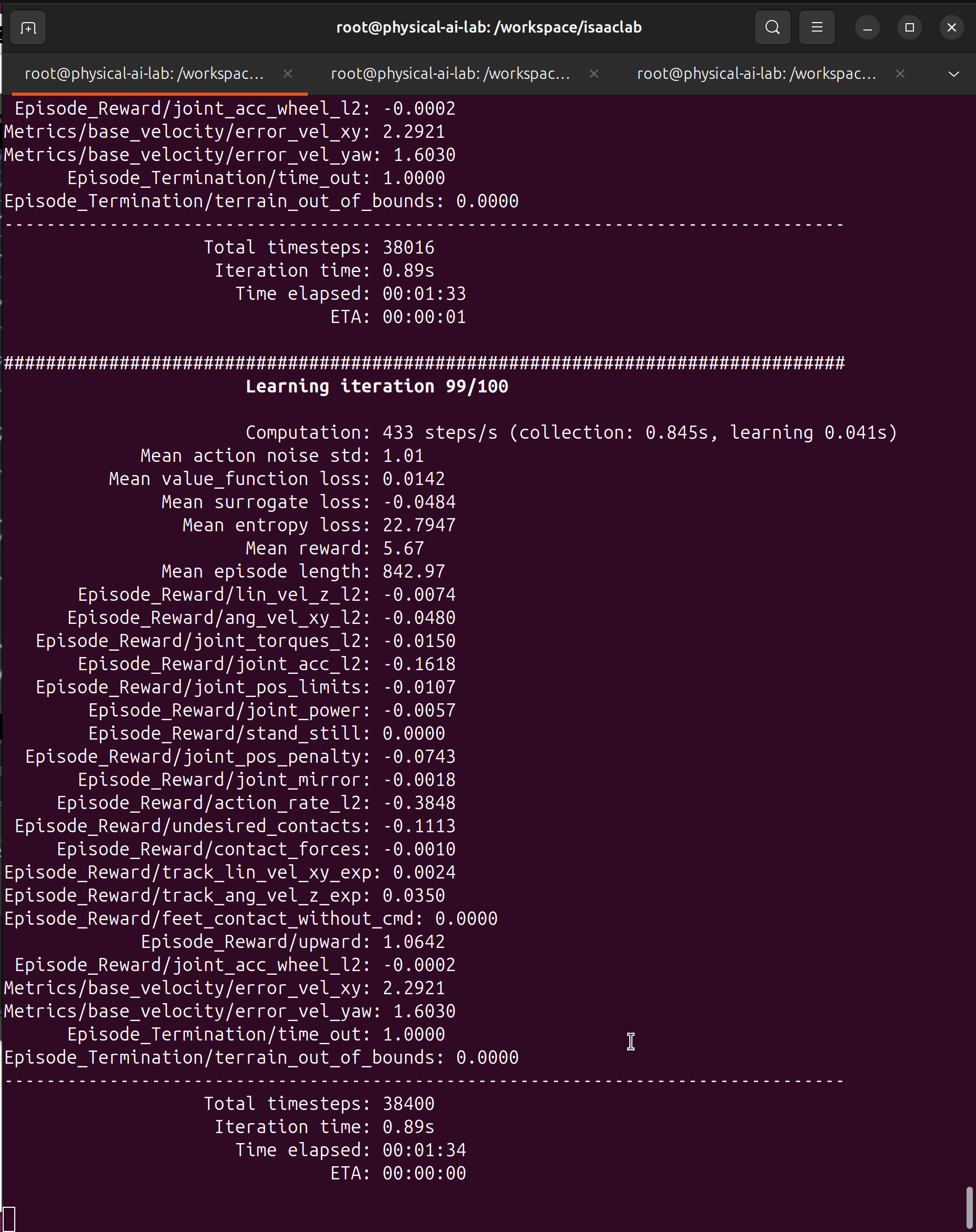
Key metrics to watch: - Mean reward: 5.67 - Positive and increasing = learning! - Mean episode length: 842 - Staying alive longer - Computation: 433 steps/s - Training speed
Evaluate Trained Policy
./isaaclab.sh -p robot_lab/scripts/reinforcement_learning/rsl_rl/play.py \
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2W-v0 \
--num_envs=16 \
--checkpoint=logs/rsl_rl/RobotLab-Isaac-Velocity-Rough-Unitree-Go2W-v0/TIMESTAMP/model_XXX.ptDomain Randomization for Sim-to-Real
Go2-W requires wheel-specific domain randomization:
Standard Randomization
| Parameter | Range | Purpose |
|---|---|---|
| Ground friction | [0.4, 1.2] | Surface variation |
| Base mass | ±2 kg | Payload changes |
| Motor strength | [0.9, 1.1] | Motor wear |
Go2-W Specific Randomization
| Parameter | Range | Purpose |
|---|---|---|
| Tire friction | [0.5, 1.25] | Rubber degradation |
| Wheel imbalance | Random vibration | Manufacturing variance |
| Tire pressure | Affects contact patch | Pressure loss |
| Wheel motor delay | [0, 20] ms | Control latency |
Monitoring Training
TensorBoard
tensorboard --logdir=logs/rsl_rl/RobotLab-Isaac-Velocity-Rough-Unitree-Go2W-v0Key Metrics for Go2-W
| Metric | Good Sign | Bad Sign |
|---|---|---|
reward/mean |
Increasing steadily | Stuck or decreasing |
episode_length |
Getting longer | Staying short (falling) |
wheel_usage |
High on flat | Always high (can’t walk) |
slip_count |
Decreasing | Staying high |
Expected Learning Curve
Reward over Training:
15 ─┐ ┌────── Converged
│ /
10 ─┤ /
│ ___/
5 ─┤ _____/
│ _____/
0 ─┼──────_____/───────────────────────────────────
│ /
-5 ─┘ / Random
└──┬────┬────┬────┬────┬────┬────┬────┬────┬────
0 200 400 600 800 1000 1200 1400 1600 1800
Iterations
Phase 1: Learn to stand (0-200)
Phase 2: Learn to roll (200-600)
Phase 3: Learn to walk (600-1000)
Phase 4: Learn hybrid transitions (1000-1800)Curriculum Learning Strategy
For best results, train Go2-W in stages:
Stage 1: Standing (velocity = 0)
# Learn to balance on wheels
--task=RobotLab-Isaac-Velocity-Flat-Unitree-Go2W-v0
# With zero velocity commands initiallyStage 2: Rolling Only
# Flat terrain, forward commands
--task=RobotLab-Isaac-Velocity-Flat-Unitree-Go2W-v0Stage 3: Walking + Rolling
# Rough terrain forces leg usage
--task=RobotLab-Isaac-Velocity-Rough-Unitree-Go2W-v0Training Logs Structure
logs/rsl_rl/RobotLab-Isaac-Velocity-Rough-Unitree-Go2W-v0/
└── YYYY-MM-DD_HH-MM-SS/
├── model_100.pt # Checkpoints (16D actions)
├── model_500.pt
├── model_1000.pt
├── events.out.tfevents* # TensorBoard logs
└── config.yaml # Training configurationTroubleshooting
Problem: Robot Always Uses Wheels (Never Walks)
Cause: Energy penalty too high, or rough terrain not challenging enough
Fix: Reduce energy penalty weight or increase terrain difficulty
Problem: Robot Never Uses Wheels
Cause: Wheel actions not properly connected, or slip penalty too high
Fix: Verify wheel joints are velocity-controlled, reduce slip penalty
Problem: Oscillating Between Modes
Cause: Mode switching penalty too low
Fix: Increase mode switching penalty to encourage commitment
Problem: Policy Not Converging
Causes: - Observation space mismatch (expecting 45D, getting 53D) - Action space mismatch (expecting 12D, getting 16D)
Fix: Verify robot_lab configuration matches Go2-W specs
Quick Reference Card
┌─────────────────────────────────────────────────────────────┐
│ GO2-W TRAINING QUICK REFERENCE │
├─────────────────────────────────────────────────────────────┤
│ │
│ INSTALL ROBOT_LAB (on HOST, with bind mount) │
│ ───────────────────────────────────────────── │
│ cd ~/docker/isaac-lab/IsaacLab │
│ git clone https://github.com/fan-ziqi/robot_lab.git │
│ # Add bind mount to docker-compose.yaml │
│ # Restart container, then inside: │
│ pip install -e robot_lab/source/robot_lab │
│ │
│ TRAINING COMMANDS (use robot_lab's scripts!) │
│ ───────────────────────────────────────────── │
│ ./isaaclab.sh -p robot_lab/scripts/.../train.py \ │
│ --task=RobotLab-Isaac-Velocity-Flat-Unitree-Go2W-v0 \ │
│ --num_envs=16 --max_iterations=100 │
│ │
│ KEY DIFFERENCES FROM GO2 │
│ ──────────────────────── │
│ Actions: 16D (not 12D) │
│ Observations: ~53D (not 45D) │
│ Control: Legs=Position, Wheels=Velocity │
│ Reward: Energy penalty → hybrid behavior │
│ │
│ MONITOR │
│ ─────── │
│ tensorboard --logdir=logs/rsl_rl/RobotLab-...-Go2W-v0 │
│ │
└─────────────────────────────────────────────────────────────┘Workshop Questions
- Optimal energy penalty weight for hybrid behavior?
- How to encourage mode transitions without oscillation?
- Best num_envs for RTX 4090 with Go2-W?
- Curriculum learning vs end-to-end training?
- How does robot_lab handle the 16D action space internally?
What’s Next
With a trained Go2-W policy, we can deploy to real hardware:
→ Part 4: Go2-W Sim-to-Real - Export and deploy the hybrid locomotion policy
Sources
- robot_lab Extension - Go2-W environments
- RSL-RL - PPO implementation
- Isaac Lab Documentation
- Proximal Policy Optimization (PPO)